PHP Strip_tags
9 posts by 3 authors in: Forums > CMS Builder
Last Post: February 24, 2013 (RSS)
By design9 - January 22, 2013
I am using the following max words coding:
<?PHP function maxWords($textOrHtml, $maxWords) {
$text = ($textOrHtml);
$words = preg_split("/\s+/", $text, $maxWords+1);
if (count($words) > $maxWords) { unset($words[$maxWords]); }
$output = join(' ', $words);
return $output;
}
?>
<?PHP echo maxWords($record['content'], 150);?>
I know how to use the strip_tags to strip the text/html. However, in this instance I only want to strip any <img> tags in the content and not all the html like line breaks, paragraphs, links, etc.
Is there a way to do that? Also, when using the max words, it is also pulling in strange characters which are not converting to html. Is there also a way to fix those - use "htmlspecialchars()" ?
Thanks!
April
Hi,
You can use this preg_replace function to only remove images:
<?php echo preg_replace("/<img[^>]+\>/i", "", maxWords($record['content'])); ?>
Could you give me an example of the strange charecters that are being pulled in?
Thanks!
Greg
PHP Programmer - interactivetools.com
By design9 - January 24, 2013
Here is a screenshot of the strange character. It looks like a "?".
Thanks!
April
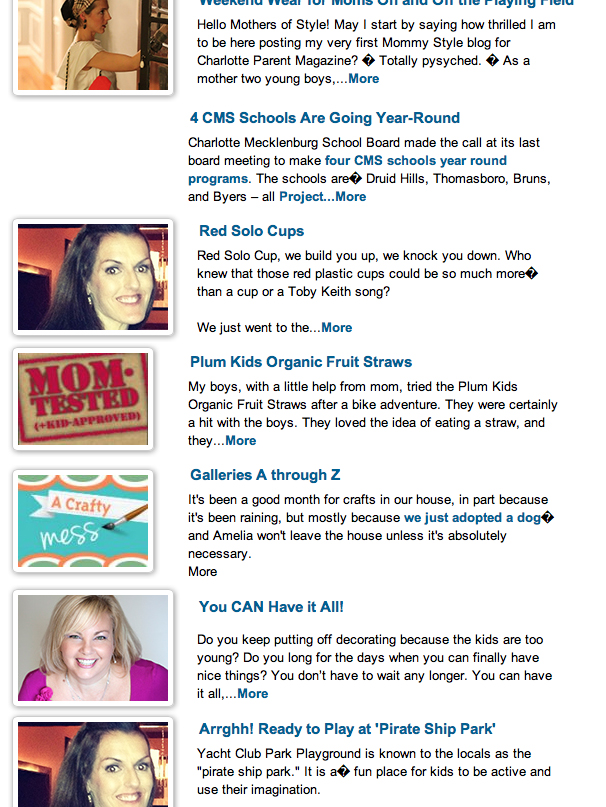{kind=link}
Hi April,
The question mark blocks usually appear when a browser is unsure how to display characters because it doesn't recognize the encoding. CMS Builder stores its data using the UTF-8 character set. Could you check the header of your page to see if the page is displaying in UTF-8? Your header should look something like this:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
Let me know if you have any questions.
Thanks!
Greg
PHP Programmer - interactivetools.com
By design9 - February 1, 2013
Yes, I am using UTF-8. However, I still get those characters. Do you know any other reason that would cause it or how to strip those characters?
Thanks!
April
Hi April,
Have you copied the text into the WYSIWYG editor from another source, for example from a word document? As sometimes this can import characters that are in the wrong format. Also, have you tried editing a record and deleting the character that isn't displayed correctly, and then adding it back in again?
Could you provide a link to the page this is happening on?
Thanks!
Greg
PHP Programmer - interactivetools.com
By design9 - February 1, 2013
Greg,
Yes, our web editors will often copy and paste content from a word document etc. I always tell them to paste using the plain paste button. When I go back into the WYSIWYG, I don't see any strange html or characters but if I backspace and delete the space where the character is showing, I can delete it. It is just a slow process. The strange thing here is the characters only show up when we use the auto-feed coding. It doesn't show up when the editors input the content directly into the home page backend area. However, I don't know if they are cleaning it up when they input manually on home vs. when it is being auto-feed straight from blog area.
This coding is on our home page and a new design page I am using. It is in the tabbed panel that says Blogs.
www.charlotteparent.com or www.charlotteparent.com/newdesign.php
Was trying to figure out a quicker way to avoid it or having to manually go into each blog post and delete where it is appearing.
Thanks!
April
Hi April,
Just had another look at the page and noticed the question mark symbols have gone. Did you manage to resolve the problem? Or did you manually change all of the records?
Thanks!
Greg
PHP Programmer - interactivetools.com
By Codee - February 24, 2013
I had a client that had several editorialists committing the same crime (er, uh "having the same problem") with pasting from Word and from Wordperfect. It would also occur with some non-apostrophe characters from time-to-time, too...such as a copyright symbol, maybe from an unusual font. A fix that worked very well for them,and especially the boss client who didn't want to fix all his editorialists work every week) was if they were going to paste copied text into the system then they added a step - first paste it into notepad or another non-word-special function based text editor (like ultra edit).. What happens in these basic text editors is that all special formatting is stripped out so that only true text characters are left. Then copy it from the notepad file into the the CMSB text boxes or WYWIWYG boxes.